Python Scrapy中文教程,Scrapy框架快速入门!
谈起爬虫必然要提起 Scrapy 框架,因为它能够帮助提升爬虫的效率,从而更好地实现爬虫。
Scrapy 是一个为了抓取网页数据、提取结构性数据而编写的应用框架,该框架是封装的,包含 request (异步调度和处理)、下载器(多线程的 Downloader)、解析器(selector)和 twisted(异步处理)等。对于网站的内容爬取,其速度非常快捷。
也许读者会感到迷惑,有这么好的爬虫框架,为什么前面的章节还要学习使用 requests 库请求网页数据。其实,requests 是一个功能十分强大的库,它能够满足大部分网页数据获取的需求。其工作原理是向服务器发送数据请求,至于数据的下载和解析,都需要自己处理,因而灵活性高;而由于 Scrapy 框架的封装,使得其灵活性降低。
至于使用哪种爬虫方式,完全取决于个人的实际需求。在没有明确需求之前,笔者依然推荐初学者先选择 requests 库请求网页数据,而在业务实战中产生实际需求时,再考虑 Scrapy 框架。
Scrapy 安装
直接使用 pip 安装 Scrapy 会产生一些错误的安装提示信息,导致 Scrapy 无法正常安装。当然,既然有问题出现,必然对应着许多的解决办法。在 http://www.lfd.uci.edu/~gohlke/pythonlibs 网站中,拥有很多适用于 Windows 的、已经编译好的 Python 第三方库,读者只需根据错误的安装提示信息找到相应的包,进行安装即可,此处不对这种方法进行详细讲解。本小节主要介绍如何在 PyCharm 中安装 Scrapy。
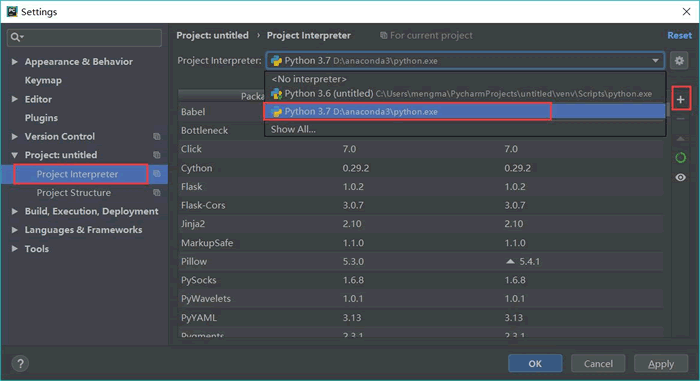
第一步,选择 Anaconda 3 作为编译环境。在 PyCharm 中单击左上角 File 选项,单击“Settings”按钮,弹出如图 1 所示界面,然后展开 Project Interpreter 的下拉菜单,选择 Anaconda 3 的下拉菜单:
和save()方法:更新或修改数据")
详解")

发表评论