返回
2022年08月13日
-
Spark Streaming的系统架构
本节首先分析传统流处理系统架构存在的问题,然后介绍 Spark Streaming 的系统架构及其工作原理和优势。
传统流处理系统架构
流处理架构的分布式流处理管道执行方式是,首先用数据采集系统接收来自数据源的流数据,然后在集群上并行处理数据,最后将处理结果存放至下游系统。
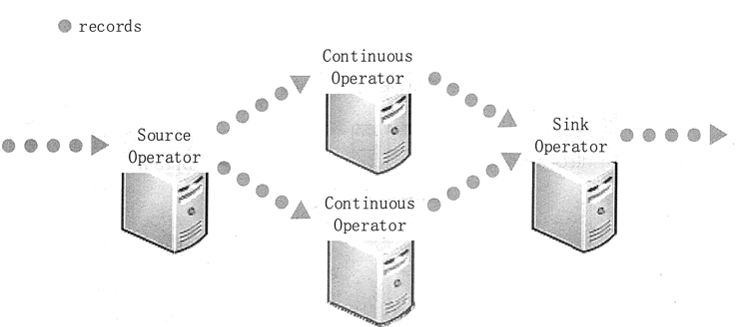
为了处理这些数据,传统的流处理系统被设计为连续算子模型,其工作方式如图 1 所示。
系统包含一系列的工作结点,每组结点上运行一至多个连续算子。对于流数据,每个连续算子(ContinuousOperator)一次处理一条记录,并且将记录传输给管道中别的算子,源算子(SourceOperator)从采集系统接收数据,接着沉算子(SinkOperator)输出到下游系统。
连续算子是一种较为简单、自然的模型。然而,在大数据时代,随着数据规模的不断扩大,以及越来越复杂的实时分析,这个传统的架构面临着严峻的挑战。