DQN算法原理及应用(实现Atari游戏)
深度 Q 网络(DQN)是将 Q learning 和卷积神经网络(CNN)结合在一起,由 Mnih 等人在 2013 年首次提出(https://arxiv.org/pdf/1312.5602.pdf)。
CNN 由于能够提取空间信息,能够从原始像素数据中学习得到控制策略。由于前面已经介绍了卷积神经网络,所以本节不再介绍基础知识。
本节内容基于原始的 DQN 论文,DeepMind 使用深度强化学习玩转 Atari,这篇论文中提到了一种称为经验回放(experience replay)的概念,随机抽样前一个游戏动作(状态、动作奖励、下一个状态)。
准备工作
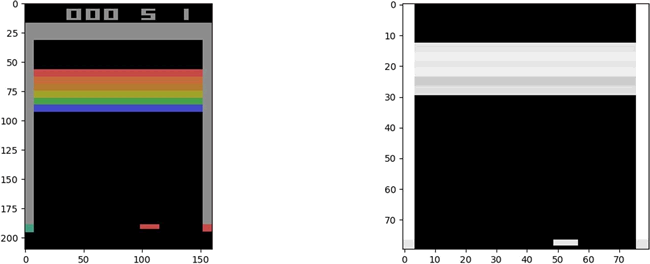
正如上一节提到的那样,对于像 Pac-Man 或 Breakout 这样的 Atari 游戏,需要预处理观测状态空间,它由 33600 个像素(RGB 的 3 个通道)组成。这些像素中的每一个都可以取 0~255 之间的任意值。preprocess 函数需要能够量化可能的像素值,同时减小观测状态空间。
这里利用 Scipy 的 imresize 函数来下采样图像。函数 preprocess 会在将图像输入到 DQN 之前,对图像进行预处理:

IM_SIZE 是一个全局参数,这里设置为 80。该函数具有描述每个步骤的注释。下面是预处理前后的观测空间:



发表评论