大数据开发涉及到的关键技术有哪些?
大数据本身是一种现象而不是一种技术。大数据技术是一系列使用非传统的工具来对大量的结构化、半结构化和非结构化数据进行处理,从而获得分析和预测结果的数据处理技术。
大数据价值的完整体现需要多种技术的协同。大数据关键技术涵盖数据存储、处理、应用等多方面的技术,根据大数据的处理过程,可将其分为大数据采集、大数据预处理、大数据存储及管理、大数据处理、大数据分析及挖掘、大数据展示等。
大数据采集技术
大数据采集技术是指通过 RFID 数据、传感器数据、社交网络交互数据及移动互联网数据等方式获得各种类型的结构化、半结构化及非结构化的海量数据。
因为数据源多种多样,数据量大,产生速度快,所以大数据采集技术也面临着许多技术挑战,必须保证数据采集的可靠性和高效性,还要避免重复数据。
大数据的数据源主要有运营数据库、社交网络和感知设备 3 大类。针对不同的数据源,所采用的数据采集方法也不相同。《大数据采集技术概述》教程中会对大数据采集技术做详细介绍。
大数据预处理技术
大数据预处理技术主要是指完成对已接收数据的辨析、抽取、清洗、填补、平滑、合并、规格化及检查一致性等操作。
因获取的数据可能具有多种结构和类型,数据抽取的主要目的是将这些复杂的数据转化为单一的或者便于处理的结构,以达到快速分析处理的目的。
通常数据预处理包含 3 个部分:数据清理、数据集成和变换及数据规约。
1)数据清理
数据清理主要包含遗漏值处理(缺少感兴趣的属性)、噪音数据处理(数据中存在错误或偏离期望值的数据)和不一致数据处理。
- 遗漏数据可用全局常量、属性均值、可能值填充或者直接忽略该数据等方法处理。
- 噪音数据可用分箱(对原始数据进行分组,然后对每一组内的数据进行平滑处理)、聚类、计算机人工检查和回归等方法去除噪音。
- 对于不一致数据则可进行手动更正。
2)数据集成
数据集成是指把多个数据源中的数据整合并存储到一个一致的数据库中。
这一过程中需要着重解决 3 个问题:模式匹配、数据冗余、数据值冲突检测与处理。
由于来自多个数据集合的数据在命名上存在差异,因此等价的实体常具有不同的名称。对来自多个实体的不同数据进行匹配是处理数据集成的首要问题。
数据冗余可能来源于数据属性命名的不一致,可以利用皮尔逊积矩来衡量数值属性,对于离散数据可以利用卡方检验来检测两个属性之间的关联。
数据值冲突问题主要表现为,来源不同的统一实体具有不同的数据值。数据变换的主要过程有平滑、聚集、数据泛化、规范化及属性构造等。
数据规约主要包括数据方聚集、维规约、数据压缩、数值规约和概念分层等。
使用数据规约技术可以实现数据集的规约表示,使得数据集变小的同时仍然近于保持原数据的完整性。
在规约后的数据集上进行挖掘,依然能够得到与使用原数据集时近乎相同的分析结果。
《大数据预处理架构和方法》教程中会对大数据预处理技术进行详细介绍。
大数据存储及管理技术
大数据存储及管理的主要目的是用存储器把采集到的数据存储起来,建立相应的数据库,并进行管理和调用。
在大数据时代,从多渠道获得的原始数据常常缺乏一致性,数据结构混杂,并且数据不断增长,这造成了单机系统的性能不断下降,即使不断提升硬件配置也难以跟上数据增长的速度。这导致传统的处理和存储技术失去可行性。
大数据存储及管理技术重点研究复杂结构化、半结构化和非结构化大数据管理与处理技术,解决大数据的可存储、可表示、可处理、可靠性及有效传输等几个关键问题。
具体来讲需要解决以下几个问题:海量文件的存储与管理,海量小文件的存储、索引和管理,海量大文件的分块与存储,系统可扩展性与可靠性。
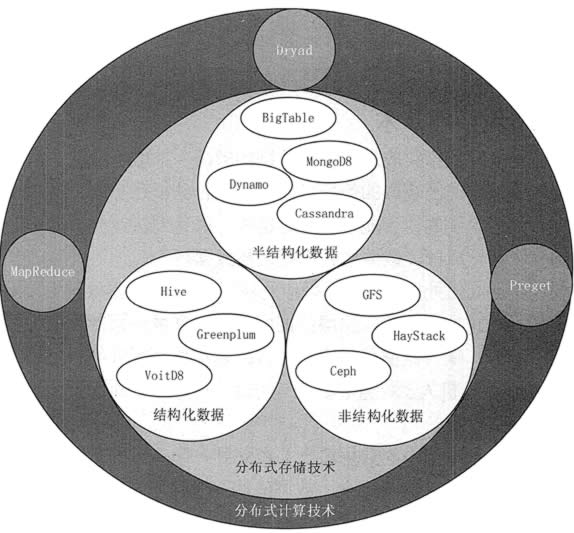
面对海量的 Web 数据,为了满足大数据的存储和管理,Google 自行研发了一系列大数据技术和工具用于内部各种大数据应用,并将这些技术以论文的形式逐步公开,从而使得以 GFS、MapReduce、BigTable 为代表的一系列大数据处理技术被广泛了解并得到应用,同时还催生出以 Hadoop 为代表的一系列大数据开源工具。
从功能上划分,这些工具可以分为分布式文件系统、NoSQL 数据库系统和数据仓库系统。这 3 类系统分别用来存储和管理非结构化、半结构化和结构化数据,如图 1 所示。



发表评论