HDFS读取和写入数据简介
HDFS 的文件访问机制为流式访问机制,即通过 API 打开文件的某个数据块之后,可以顺序读取或者写入某个文件。由于 HDFS 中存在多个角色,且对应的应用场景主要为一次写入、多次读取的场景,因此其读和写的方式有较大不同。读/写操作都由客户端发起,并且由客户端进行整个流程的控制,NameNode 和 DataNode 都是被动式响应。
读取流程
客户端发起读取请求时,首先与 NameNode 进行连接。
连接建立完成后,客户端会请求读取某个文件的某一个数据块。NameNode 在内存中进行检索,查看是否有对应的文件及文件块,若没有则通知客户端对应文件或数据块不存在,若有则通知客户端对应的数据块存在哪些服务器之上。
客户端接收到信息之后,与对应的 DataNode 连接,并开始进行数据传输。客户端会选择离它最近的一个副本数据进行读操作。
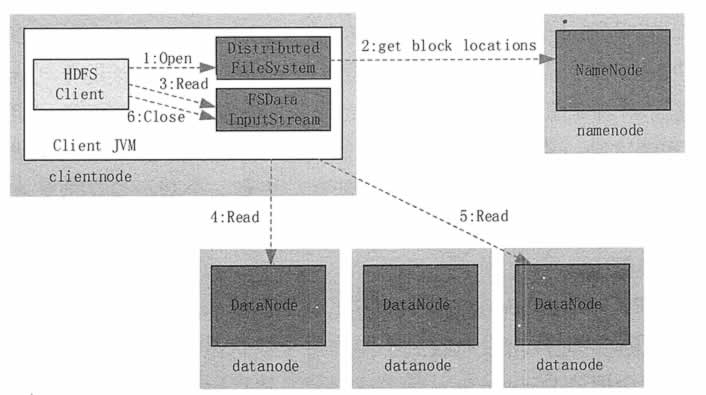
如图 1 所示,读取文件的具体过程如下。
1) 客户端调用 DistributedFileSystem 的 Open() 方法打开文件。
2) DistributedFileSystem 用 RPC 连接到 NameNode,请求获取文件的数据块的信息;NameNode 返回文件的部分或者全部数据块列表;对于每个数据块,NameNode 都会返回该数据块副本的 DataNode 地址;DistributedFileSystem 返回 FSDataInputStream 给客户端,用来读取数据。
3) 客户端调用 FSDataInputStream 的 Read() 方法开始读取数据。
4) FSInputStream 连接保存此文件第一个数据块的最近的 DataNode,并以数据流的形式读取数据;客户端多次调用 Read(),直到到达数据块结束位置。
5) FSInputStream连接保存此文件下一个数据块的最近的 DataNode,并读取数据。
6) 当客户端读取完所有数据块的数据后,调用 FSDataInputStream 的 Close() 方法。
详解")
")

发表评论