C语言/C++字符编码方式解析
本节对操作系统里的字符编码进行简单介绍,这对于程序的跨平台开发、汉字乱码问题解决等都是很重要的知识,了解这些知识就不再害怕遇到程序乱码的问题了。
ANSI 多字节编码
在最早的时期,计算机只支持英文字符,那时都是用 ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)编码,一个字母或符号只需要一个字节存储。随着计算机的推广应用,越来越多的国家和地区面临本地语言文字如何在计算机里使 用和显示的问题。对于中文 DOS 系统和早期的中文 Windows 系统,大陆制定了国标码 GB2312,台港澳地区则使用了大五码 Big5。微软针对这些本地化字符编码采用的就是用 ANSI(American National Standards Institute,美国国家标准学会)多字节编码方式,系统里的英文和符号就使用单字节的 ASCII(0x00~0x7f),而对于汉字之类的本地化字符编码,就采用 0x80~0xFF 范围内的多个字节来表示,这样既能兼容 ASCII ,又能正常使用本地化语言文字。
大陆的国标码发展了好几代,归结如下:
| 中文字符编码 | 说明 |
|---|---|
| GB2312 | 1980 年发布,收录了 7445 个字符,包括 6763 个汉字和 682 个其它符号。汉字是双字节编码。 |
| GBK | 1995 年发布,收录了 21886 个符号,包括 21003 个汉字和 883 个其它符号。汉字是双字节编码。简体中文 Windows 目前默认采用这种本地化编码。 |
| GB18030-2000 | 2000 年发布,收录了 27533 个汉字,汉字分为双字节编码部分和四字节编码部分。 |
| GB18030-2005 | 2005 年发布,收录了 70244 个汉字,汉字也分为双字节编码部分和四字节编码部分。 |
新的国标码标准通常是兼容旧的编码方式的,所以一般对简体中文的文本选择 GBK 或 GB18030 编码都是可以正常显示的。微软针对各种本地化语言的页面有自己的编号方式,GBK 对应的代码页编号是 936,GB18030 对应的代码页编号是 54936,Big5 对应的代码页编号是 950。
关于汉字编码可以参考:http://www.fmddlmyy.cn/text24.html
关于代码页编号可以参考:http://zh.wikipedia.org/wiki/%E4%BB%A3%E7%A0%81%E9%A1%B5
Unicode 系列编码
ANSI 多字节编码解决了各种语言文字的本地化使用问题,也有它自己的缺陷:各地制定的编码标准只对自己的语言文字有效,而不同语言文字的编码都是冲突的,因为大家都用 0x80~0xFF 范围字节表示自己的语言文字,而不考虑别的语言文字如何编码,冲突在所难免。比如简体中文(GBK)的文本放到繁体中文(Big5)的操作系统里,就被默认解析成繁体字编码,两种编码是冲突的,就会显示混乱的繁体字,反过来也一样。
因此国际组织制定了 Unicode 编码,也叫万国码、国际码等,这种字符编码是对全球语言统一分配编码区间,各种语言字符互相不冲突,都可以兼容使用。Unicode 编码从最初的 1.0,慢慢发展到今年发布的 8.0,包含的语言文字越来越多。
Unicode 编码系统,可分为编码方式和实现方式两个层次。对于国际组织发布的 Unicode 编码标准,对应的就是编码方式,最常用的是 UCS-2(Universal Character Set 2),采用两字节编码一个字符。当然国际语言文字太多,两字节不够用了,就有四字节编码方式 UCS-4。这个仅仅是标准,而不是实现,在编码实现的过程中,有些考虑兼容旧的单字节 ASCII 编码,有些不考虑兼容性;有些考虑双字节中哪个字节放在前面,哪个字节放在后面的问题,即 BOM(Byte Order Mark,字节顺序标记)的作用。因此诞生了多种国际码的实现方式,统称为 Unicode 转换格式(Unicode Transformation Format,UTF):
| Unicode 转换格式 | 说明 |
|---|---|
| UTF-8 | 灵活的变长编码,对于 ASCII 使用一个字节编码,其他本地化语言文字用多个字节编码,最长可以到 6 个字节编码一个字符。对于汉字,通常是 3 个字节表示一个汉字。这是 Unix/Linux 系统默认的字符编码。 |
| UTF-16 | 兼容 UCS-2,一般都是两字节表示一个字符,对于超出两字节的国际码字符,使用一对两字节来表示。在存储时,按两个字节的排布顺 序,可以分为 UTF-16LE(Little Endian,小端字节序)和UTF-16BE(Big Endian,大端字节序),微软所说的 Unicode 默认就是 UTF-16LE。 |
| UTF-32 | 同 UCS-4,因为用四个字节表示一个字符,所以不需要考虑扩展了。这种编码方式简单,但也特别浪费空间,所以应用很少。在存储时也分为 UTF-32BE 和 UTF-32LE,因为用得少,所以不用太关心这种编码格式。 |
关于 Unicode 编码格式参考:http://baike.baidu.com/view/40801.htm
关于 UTF 和 BOM 参考:http://www.unicode.org/faq/utf_bom.html
C++使用的字符串
在 C++ 中,以前通常使用 char 表示单字节的字符,使用 wchar_t 表示宽字符,对国际码提供一定程度的支持。 char * 字符串有专门的封装类 std::string 来处理,标准输入输出流是 std::cin 和 std::cout 。对于 wchar_t * 字符串,其封装类是 std::wstring,标准输入输出流是 wcin 和 wcout。
虽然规定了宽字符,但是没有明确一个宽字符是占用几个字节,Windows 系统里的宽字符是两个字节,就是 UTF-16;而 Unix/Linux 系统里为了更全面的国际码支持,其宽字符是四个字节,即 UTF-32 编码。这为程序的跨平台带来一定的混乱,除了 Windows 程序开发常用 wchar_t* 字符串表示 UTF-16 ,其他情况下 wchar_t* 都用得比较少。
MFC 一般用自家的 TCHAR 和 CString 类支持国际化,当没有定义 _UNICODE 宏时,TCHAR = char,当定义了 _UNICODE宏 时,TCHAR = wchar_t,CString 内部也是类似的。Qt 则用 QChar 和 QString 类(内部恒定为 UTF-16),一般的图形开发库都用自家的字符串类库。
在新标准 C++11 中,对国际码的支持做了明确的规定:
- char * 对应 UTF-8 编码字符串(代码表示如 u8"多种文字"),封装类为 std::string;
- 新增 char16_t * 对应 UTF-16 编码字符串(代码表示如 u"多种文字"),封装类为 std::u16string ;
- 新增 char32_t * 对应 UTF-32 编码字符串(代码表示如 U"多种文字"),封装类为 std::u32string 。
因为 Qt 有封装好的 QString,所以不太需要这些新增的字符串格式。关于 C++11 字符串更详细的内容参考:http://blog.poxiao.me/p/unicode-character-encoding-conversion-in-cpp11/
源文件字符编码测试
在 Windows 系统里最常用的文本字符编码格式是 ANSI (简体是 GBK,繁体是 Big5)和 Unicode (UTF-16LE)格式,Windows 命令行默认的输入输出格式是 ANSI 的。在 Linux 系统里统统都是 UTF-8 ,这个比较省心。
Windows 自带的记事本,以及 Notepad++ 工具、Linux 系统里的 kwrite、gedit 等都支持各种编码格式的文本显示。以 Windows 记事本为例,打开任意一个文本文件,选择菜单“文件 --> 另存为”,点开“另存为”对话框最下面的“编码”:
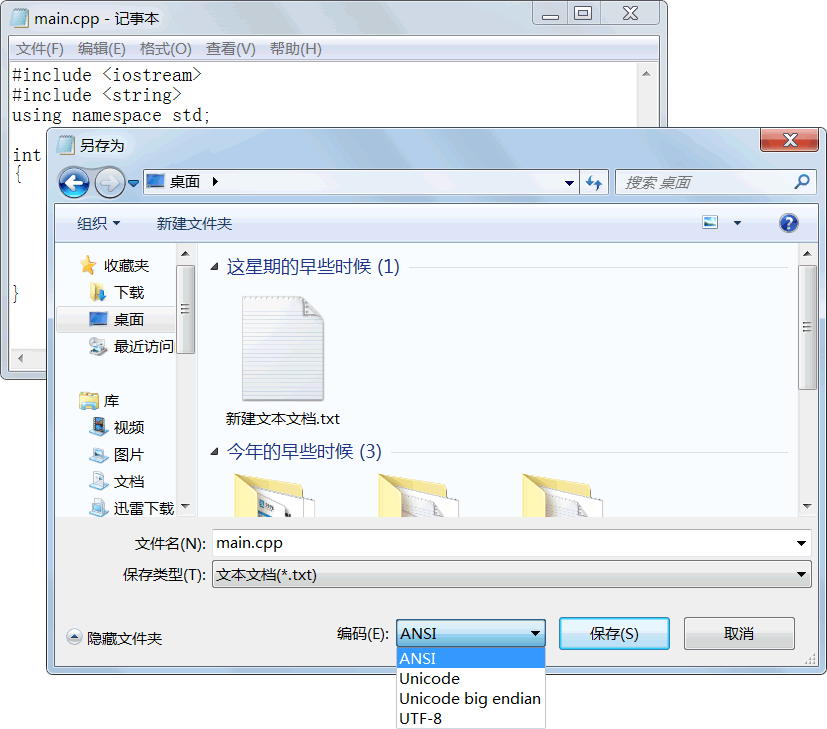



发表评论