流迭代器实现文件操作(读取和写入)方法详解
流迭代器并不知道底层流的特性。当然,它们只适用于文本模式,否则它们不会关心数据是什么。流迭代器可以以文本模式来读写任何类型的流。这意味着除了其他的一些流之外,我们可以用迭代器以文本模式来读和写文件。在深入讲解如何对文件使用流迭代器之前,需要提醒你文件流的一些本质特征以及如何生成一个封装了文件的流对象。
文件流
文件流封装了一个实际的文件。文件流有长度,也就是这个流中字符的个数,因此对于新的输出文件,长度就是 0;文件流有起始位置,起始位置是流中索引为 0 的第一个字符的索引;文件流也有结束位置,结束位置是文件流中最后一个字符的下一个位置。文件流还有当前位置,是下一个写或读操作的开始位置的索引。可以以文本模式或二进制模式将数据转移到文件中或从文件中读出来。
在文本模式下,数据是字符的序列。可以用提取和插入运算符来读写数据,至少对于输入来说,数据项必须由一个或多个空格隔开。数据经常被写成以 '\n' 终止的连续行。一些系统,例如微软的 Windows 系统,在读写时会转换换行符。在读到回车和换行符时,它们会被映射到单个字符 '\n'。在另一些系统中,换行符被当作单个字符读写。因此,文件输入流的长度依赖于它们所来自的系统环境。
在二进制模式下,内存和流之间是以字节的形式传送数据的,不需要转换。流迭代器只能工作在文本模式下,因此不能用流迭代器来读写二进制文件。本章后面要介绍的流缓冲迭代器,可以读写二进制文件。
尽管在二进制模式下,从内存中读取和写入的字节从来不会改变,但当谈到处理写到不同系统中的二进制文件时,仍然会有很多陷阱。一个考虑是,写文件的系统的字节顺序和读文件的系统的字节顺序是相反的。字节顺序决定了内存中字的写入顺序。
在小端字节序的处理器中,例如英特尔的 X86 处理器,最低位的字节在最低的地址,所以字节的写入顺序是从最底字节到最髙字节。在大端字节序的处理器中,例如 EBM 大型机,比特的顺序是相反的,最高字节在最低位置,因此它们的文件会出现和小端字节序的处理器相反的顺序。因此,当在小端字节序的系统中读来自于大端字节序的系统中的二进制文件时,需要考虑字节序的差别。
注意,大端字节序也被称为网络字节序,因为数据一般是以大端序在互联网上传输的。
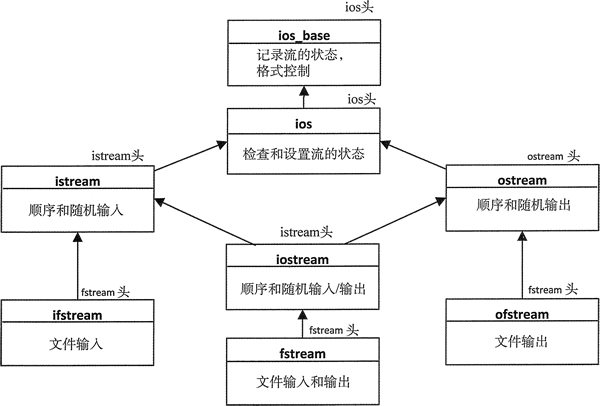
文件流类的模板
这里有 3 个表示文件流的类模板:
- ifstream:表示文件的输出流;
- ofstream:是为输出定义的文件流;
- fstream:定义了可以读和写的文件流;
这些类的继承关系如图 1 所示。
")


发表评论