浅谈感知机与神经网络(无师自通)
最近十年以来,神经网络一直处于机器学习研究和应用的前沿。深度神经网络(DNN)、迁移学习以及计算高效的图形处理器(GPU)的普及使得图像识别、语音识别甚至文本生成领域取得了重大进展。
神经网络受人类大脑的启发,也被称为连接模型。像人脑一样,神经网络是大量被称为权重的突触相互连接的人造神经元的集合。
就像我们通过年长者提供的例子来学习一样,人造神经网络通过向它们提供的例子来学习,这些例子被称为训练数据集。有了足够数量的训练数据集,人造神经网络可以提取信息,并用于它们没有见过的数据。
神经网络并不是最近才出现的。第一个神经网络模型 McCulloch Pitts(MCP)(http://vordenker.de/ggphilosophy/mcculloch_a-logical-calculus.pdf)早在 1943 年就被提出来了,该模型可以执行类似与、或、非的逻辑操作。
MCP 模型的权重和偏置是固定的,因此不具备学习的可能。这个问题在若干年后的 1958 年由 Frank Rosenblatt 解决(https://blogs.umass.edu/brain-wars/files/2016/03/rosenblatt-1957.pdf)。他提出了第一个具有学习能力的神经网络,称之为感知机(perceptron)。
从那时起,人们就知道添加多层神经元并建立一个深的、稠密的网络将有助于神经网络解决复杂的任务。就像母亲为孩子的成就感到自豪一样,科学家和工程师对使用神经网络(https://www.youtube.com/watch?v=jPHUlQiwD9Y)所能实现的功能做出了高度的评价。
这些评价并不是虚假的,但是由于硬件计算的限制和网络结构的复杂,当时根本无法实现。这导致了在 20 世纪 70 年代和 80 年代出现了被称为 AI 寒冬的时期。在这段时期,由于人工智能项目得不到资助,导致这一领域的进展放缓。
随着 DNN 和 GPU 的出现,情况发生了变化。今天,可以利用一些技术通过微调参数来获得表现更好的网络,比如 dropout 和迁移学习等技术,这缩短了训练时间。最后,硬件公司提出了使用专门的硬件芯片快速地执行基于神经网络的计算。
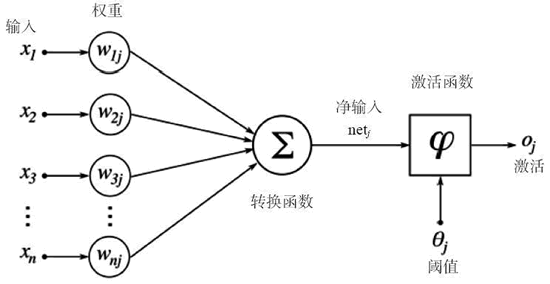
人造神经元是所有神经网络的核心。它由两个主要部分构成:一个加法器,将所有输入加权求和到神经元上;一个处理单元,根据预定义函数产生一个输出,这个函数被称为激活函数。每个神经元都有自己的一组权重和阈值(偏置),它通过不同的学习算法学习这些权重和阈值:
方法详解")

详解")
发表评论