VGGNet、ResNet、Inception和Xception图像分类及对比
图像分类任务是一个典型的深度学习应用。人们对这个任务的兴趣得益于 ImageNet 图像数据集根据 WordNet 层次结构(目前仅有名词)组织,其中检索层次的每个节点包含了成千上万张图片。
更确切地说,ImageNet 旨在将图像分类并标注为近 22000 个独立的对象类别。在深度学习的背景下,ImageNet 一般是指论文“ImageNet Large Scale Visual Recognition Challenge”中的工作,即 ImageNet 大型视觉识别竞赛,简称 ILSVRC。
在这种背景下,目标是训练一个模型,可以将输入图像分类为 1000 个独立的对象类别。本节将使用由超过 120 万幅训练图像、50000 幅验证图像和 100000 幅测试图像预训练出的模型。
VGG16和VGG19
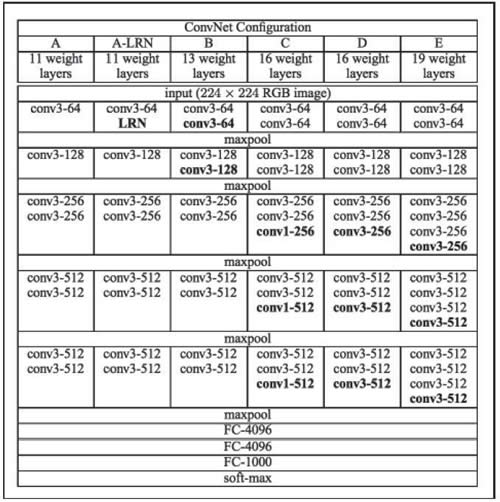
VGG16 和 VGG19 网络已经被引用到“Very Deep Convolutional Networks for Large Scale Image Recognition”(由 Karen Simonyan 和 Andrew Zisserman 于2014年编写)。该网络使用 3×3 卷积核的卷积层堆叠并交替最大池化层,有两个 4096 维的全连接层,然后是 softmax 分类器。16 和 19 分别代表网络中权重层的数量(即列 D 和 E):



发表评论