Q learning原理及实现(Cart-Pole平衡游戏)详解
前面提到过,有一个由状态 s 描述的环境(s∈S,S 是所有可能状态的集合),一个能够执行动作 a 的 agent(a∈A,A 是所有可能动作的集合),智能体的动作致使智能体从一个状态转移到另外一个状态。智能体的行为会得到奖励,而智能体的目标就是最大化奖励。
在 Q learning 中,智能体计算能够最大化奖励 R 的状态-动作组合,以此学习要采取的动作(策略 π),在选择动作时,智能体不仅要考虑当前的奖励,还要尽量考虑未来的奖励:
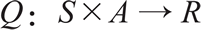

:随机打乱数组")

发表评论