HTML DOM是什么
在 HTML 中 DOM(文档对象模型)是 Web 前端里最基础、最常用的—模型。例如,一个网页其实就是一个 HTML 文件,经过浏览器的解析,最终呈现在用户面前。
HTML 语言是由很多标签组成的,代码如下所示:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>程序员天天说的DOM到底是什么</title>
</head>
<body>
<h1>我的第一个标题</h1>
<p>我的第一个段落</p>
</body>
</html>
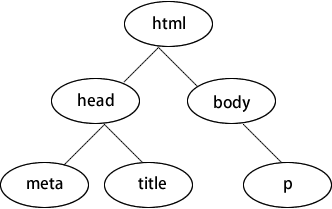
上述代码中,head 和 body 是标签。这些标签不是随意摆放的,它们有自己的规则。首先,它们是嵌套的,一层套一层,比如 html 套 body,body 又套 h1。
其次, 每一层可以同时存在很多标签,比如 head 和 body 属于同一层,它们被外面的 html 套着。这样的结构很像计算机里的文件夹。例如,“我的电脑”是最外层,里面套着 C、D、E、F 盘,每个盘里又有很多文件夹,文件夹里又有文件夹,逐个打开后才能看到具体的文件。
为什么要按照这种结构来组织呢?目的其实是方便解析和查询。解析的时候,从外向里循序渐进,好比按照图纸盖房子,先盖围墙,再盖走廊,最后才盖卧室。查询的时候,会遵循一条明确的路线,例如“D盘/文化交流/影视作品/给产品经理讲技术avi”,一层一层地缩小范围,查找效率会非常高。
所以,浏览器在解析 HTML 文档时,会把每个标签抽象成代码里的对象,按照这种层次分明的结构组织,这就是 DOM。
如下图所示为数据结构里典型的“树”结构。程序员经常说的 DOM 树,其实就是这个意思。浏览器在解析 HTML 时,会在它的内部构建这样一棵 DOM 树,然后按照这棵树上的层次顺序解析每个标签。解析完成后,用户就看到了网页的内容。


")
发表评论