Hadoop MapReduce架构
Hadoop MapReduce 是 Hadoop 平台根据 MapReduce 原理实现的计算框架,目前已经实现了两个版本,MapReduce 1.0 和基于 YARN 结构的 MapReduce 2.0。
尽管 MapReduce 1.0 中存在一些问题,但是整体架构比较清晰,更适合初学者理解 MapReduce 的核心概念。所以,本教程首先使用 MapReduce 1.0 来介绍 MapReduce 的核心概念,然后再在此基础上介绍 MapReduce 2.0。
一个 Hadoop MapReduce 作业(job)的基本工作流程就是,首先把存储在 HDFS 中的输入数据集切分为若干个独立的数据块,由多个 Map 任务(Task)以完全并行的方式处理这些数据块。
MapReduce 框架会对 Map 任务的输出先进行排序,然后把结果作为输入传送给 Reduce 任务。
一般来讲,每个 Map 和 Reduce 任务都会运行在集群的不同结点上,从而发挥集群的整体能力。作业的输入和输出通常都存储在文件系统中。
MapReduce 框架负责整个任务的调度和监控,以及重新执行失败的任务。
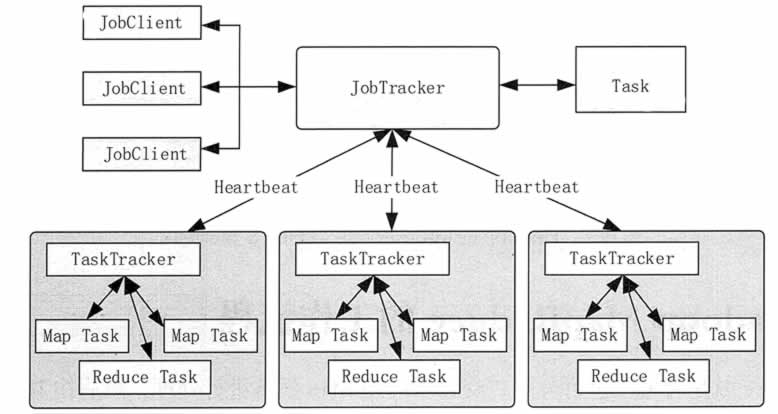
Hadoop MapReduce 1.0 的架构如图 1 所示,由 Client(客户端)、JobTracker(作业跟踪器)、TaskTracker(任务跟踪器)、Task(任务)组成。


简明教程")
发表评论