DBSCAN聚类算法简介
DBSCAN(Density—Based Spatial Clustering of Application with Noise)算法是一种典型的基于密度的聚类方法。它将簇定义为密度相连的点的最大集合,能够把具有足够密度的区域划分为簇,并可以在有噪音的空间数据集中发现任意形状的簇。
1. 基本概念
DBSCAN 算法中有两个重要参数:Eps 和 MmPtS。Eps 是定义密度时的邻域半径,MmPts 为定义核心点时的阈值。
在 DBSCAN 算法中将数据点分为以下 3 类。
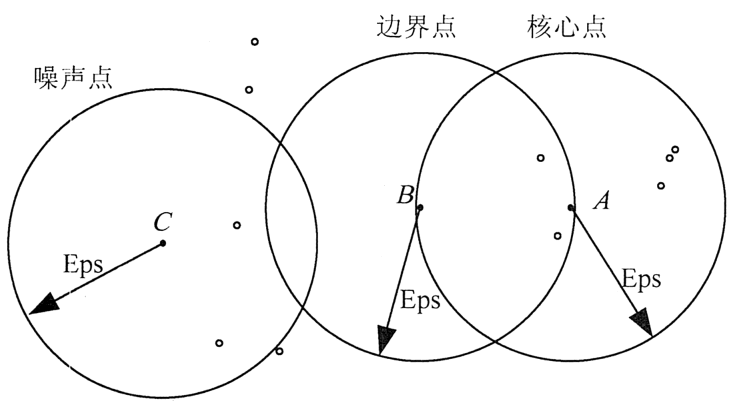
1)核心点
如果一个对象在其半径 Eps 内含有超过 MmPts 数目的点,则该对象为核心点。
2)边界点
如果一个对象在其半径 Eps 内含有点的数量小于 MinPts,但是该对象落在核心点的邻域内,则该对象为边界点。
3)噪音点
如果一个对象既不是核心点也不是边界点,则该对象为噪音点。
通俗地讲,核心点对应稠密区域内部的点,边界点对应稠密区域边缘的点,而噪音点对应稀疏区域中的点。
在图 1 中,假设 MinPts=5,Eps 如图中箭头线所示,则点 A 为核心点,点 B 为边界点,点 C 为噪音点。点 A 因为在其 Eps 邻域内含有 7 个点,超过了 Eps=5,所以是核心点。
点 E 和点 C 因为在其 Eps 邻域內含有点的个数均少于 5,所以不是核心点;点 B 因为落在了点 A 的 Eps 邻域内,所以点 B 是边界点;点 C 因为没有落在任何核心点的邻域内,所以是噪音点。


")
发表评论