GFS、MapReduce和BigTable:Google的三种大数据处理系统
Google 在搜索引擎上所获得的巨大成功,很大程度上是由于采用了先进的大数据管理和处理技术。Google 的搜索引擎是针对搜索引擎所面临的日益膨胀的海量数据存储问题,以及在此之上的海量数据处理问题而设计的。
众所周知,Google 存储着世界上最庞大的信息量(数千亿个网页、数百亿张图片)。但是,Google 并未拥有任何超级计算机来处理各种数据和搜索,也未使用 EMC 磁盘阵列等高端存储设备来保存大量的数据。
2006 年,Google 大约有 45 万台服务器,到 2010 年增加到了 100 万台,截至 2018 年,据说已经达到上千万台,并且还在不断增长中。不过这些数量巨大的服务器都不是什么昂贵的高端专业服务器,而是非常普通的 PC 级服务器,并且采用的是 PC 级主板而非昂贵的服务器专用主板。
Google 提出了一整套基于分布式并行集群方式的基础架构技术,该技术利用软件的能力来处理集群中经常发生的结点失效问题。
Google 使用的大数据平台主要包括 3 个相互独立又紧密结合在一起的系统:Google 文件系统(Google File System,GFS),针对 Google 应用程序的特点提出的 MapReduce 编程模式,以及大规模分布式数据库 BigTable。
GFS
一般的数据检索都是用数据库系统,但是 Google 拥有全球上百亿个 Web 文档,如果用常规数据库系统检索,数据量达到 TB 量级后速度就非常慢了。正是为了解决这个问题,Google 构建出了 GFS。
GFS 是一个大型的分布式文件系统,为 Google 大数据处理系统提供海量存储,并且与 MapReduce 和 BigTable 等技术结合得十分紧密,处于系统的底层。它的设计受到 Google 特殊的应用负载和技术环境的影响。相对于传统的分布式文件系统,为了达到成本、可靠性和性能的最佳平衡,GFS 从多个方面进行了简化。
GFS 使用廉价的商用机器构建分布式文件系统,将容错的任务交由文件系统来完成,利用软件的方法解决系统可靠性问题,这样可以使得存储的成本成倍下降。
由于 GFS 中服务器数目众多,在 GFS 中,服务器死机现象经常发生,甚至都不应当将其视为异常现象。所以,如何在频繁的故障中确保数据存储的安全,保证提供不间断的数据存储服务是 GFS 最核心的问题。
GFS 的独特之处在于它采用了多种方法,从多个角度,使用不同的容错措施来确保整个系统的可靠性。
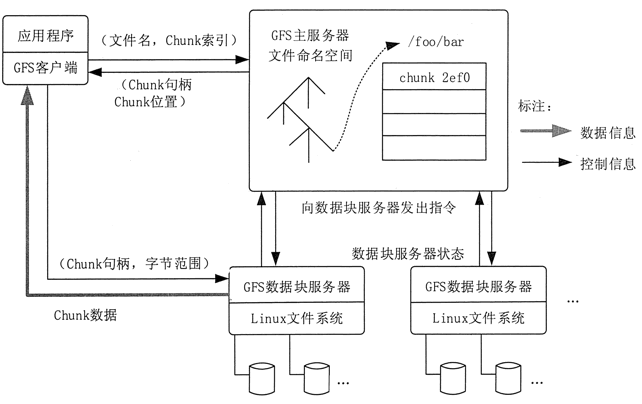
GFS 的系统架构如图 1 所示,主要由一个 Master Server(主服务器)和多个 Chunk Server(数据块服务器)组成。
Master Server 主要负责维护系统中的名字空间,访问控制信息,从文件到块的映射及块的当前位置等元数据,并与 Chunk Server 通信。
Chunk Server 负责具体的存储工作。数据以文件的形式存储在 Chunk Server 上。Client 是应用程序访问 GFS 的接口。
详解")
")

发表评论